Implementing Agentic Workflows for Java-to-Node.js Migration

Legacy migration is the “dark matter” of software engineering: we know it makes up a massive portion of the enterprise universe, yet we struggle to observe it directly without getting sucked into a black hole of regression testing and lost business logic.
For the last decade, the migration of monolithic Java Spring Boot applications to microservices-based Node.js architectures (typically running on Kubernetes) has been a manual, high-friction endeavor. The “Strangler Fig” pattern is reliable, but slow.
However, the emergence of Agentic Workflows—specifically Large Language Models (LLMs) integrated into a loop of reasoning, tool execution, and environment feedback—has fundamentally altered the economics of refactoring. We are no longer talking about “code translation” (a simple syntax swap). We are talking about semantic migration with self-healing capabilities.
This post details the architecture and implementation of a specialized “Migration Agent” designed to convert strong-typed Spring Boot applications into idiomatic Node.js services (using NestJS as the target due to its structural parity with Spring). We will explore AST parsing, paradigm mapping, and the critical Plan, Transpile, Verify feedback loop.
Architecture: The Migration Agent
The flaw in using a standard LLM chat interface for migration is context limits and hallucination. You cannot paste a 50,000-line codebase into a context window and expect a working application.
Instead, we treat the migration as a multi-step agentic workflow. The agent acts as an orchestrator that utilizes specific tools:
- File System Readers: To traverse the repo.
- AST Parsers: To understand the structure of the code, not just the text.
- Transpilers: To generate the initial draft.
- Test Runners: To execute the generated code.
- Debuggers: To analyze stack traces.
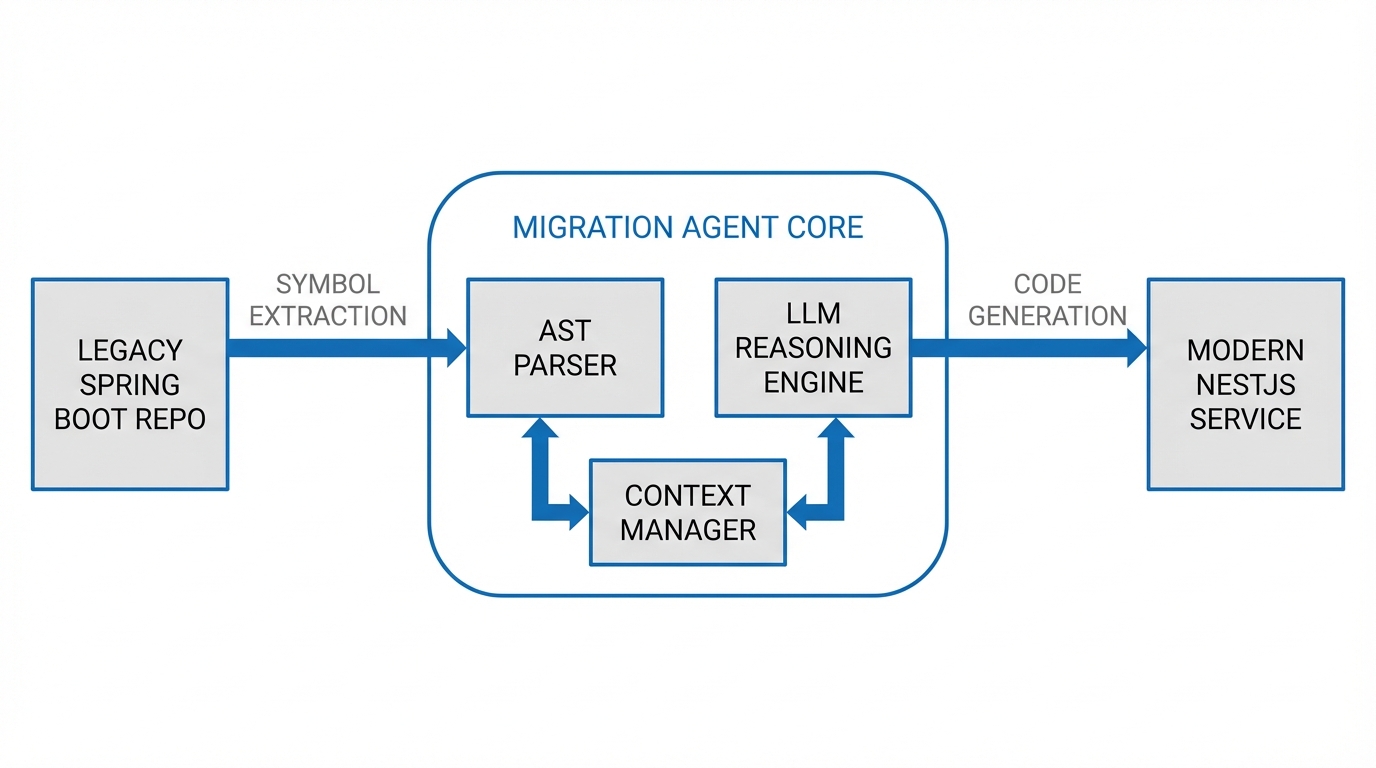
The architecture is split into three distinct phases: Discovery, Transpilation, and Verification (The Self-Healing Loop).
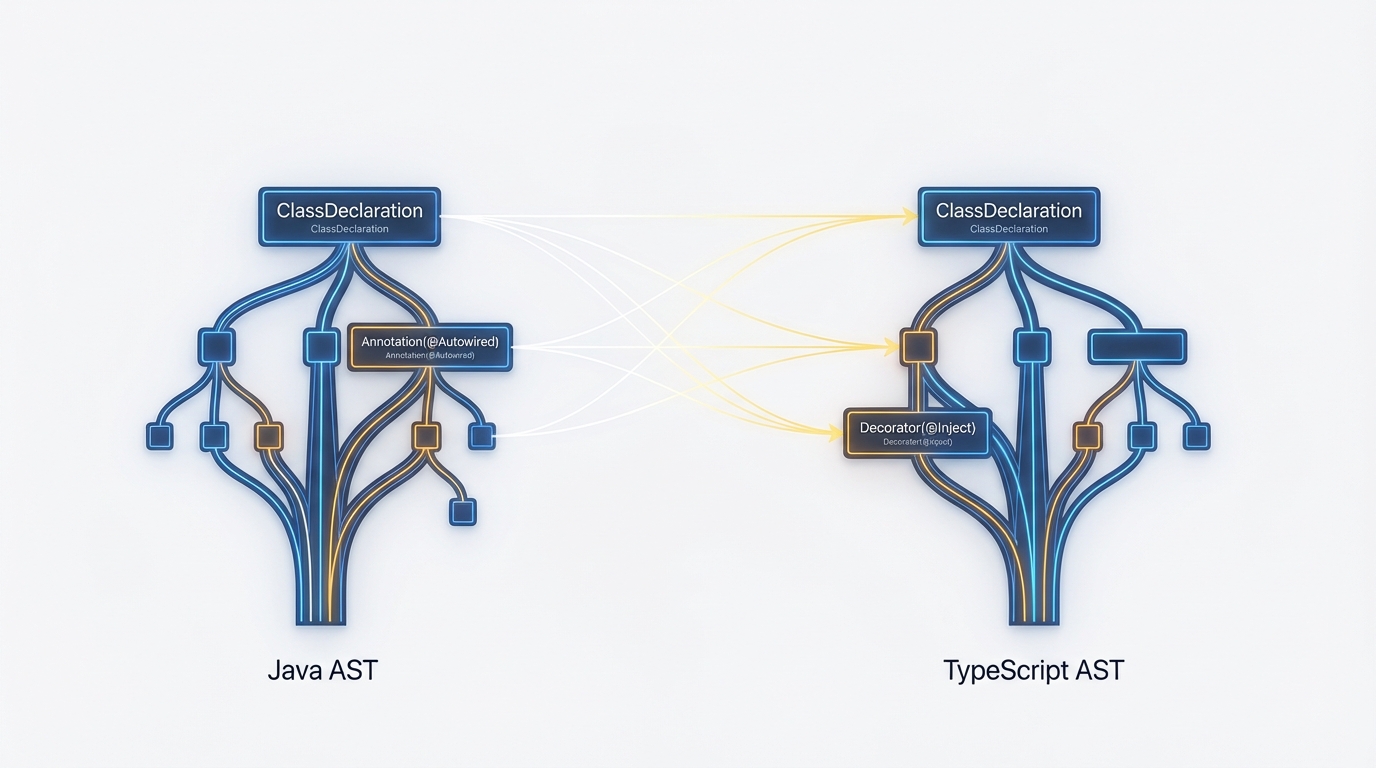
Phase 1: Discovery via AST (Abstract Syntax Tree)
Regex is insufficient for parsing Java. You cannot reliably identify dependency injection chains or transaction boundaries using string matching. We must construct an Abstract Syntax Tree (AST) of the source Java code to build a dependency graph.
We utilize tools like JavaParser (wrapped in a Python or Node script) to extract metadata before the LLM even sees the code.
Why AST matters
When migrating a Service class, the Agent needs to know:
- What other classes does this inject? (
@Autowired) - Does it use Aspect-Oriented Programming (AOP)? (
@Transactional) - What are the return types?
Here is a Python snippet using a wrapper around a Java parser to extract class signatures to feed into the Agent’s “Context Memory”:
import javalang
def parse_java_structure(file_content):
tree = javalang.parse.parse(file_content)
structure = {
"package": str(tree.package.name),
"imports": [],
"classes": []
}
# Extract Imports
for imp in tree.imports:
structure["imports"].append(imp.path)
# Extract Class Metadata
for type_decl in tree.types:
class_info = {
"name": type_decl.name,
"annotations": [a.name for a in type_decl.annotations],
"methods": []
}
# specific logic to find Dependency Injection
for field in type_decl.fields:
if "Autowired" in [a.name for a in field.annotations]:
class_info["dependencies"] = str(field.type.name)
structure["classes"].append(class_info)
return structure
By running this across the entire Java project, the Agent builds a Topological Sort of the application. It knows it must migrate the DTOs and Entities first, then the Repositories, then Services, and finally the Controllers.
Phase 2: The Core Loop (Plan, Transpile, Verify)
Once the dependency graph is established, the Agent enters its core execution loop. This is not a linear “read-write” operation. It is recursive.
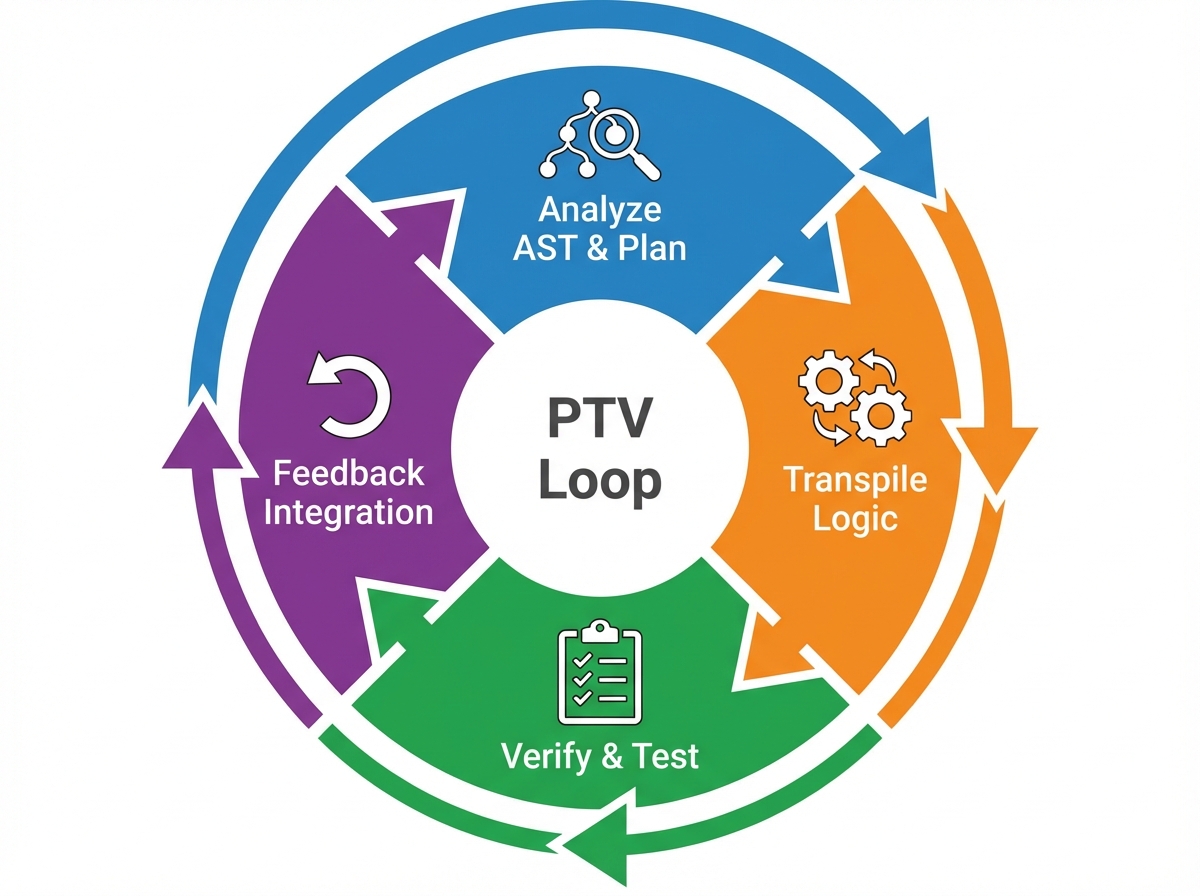
The Planner Agent
The Planner does not write code. It analyzes the Java file and the AST metadata to create a “Migration Specification.”
- Input:
UserService.java - Output: JSON Spec
- Target Framework: NestJS
- Dependencies: TypeORM, generic-pool
- Async Strategy:
async/await(replace blocking I/O)
The Transpiler (Paradigm Mapping)
This is where the semantic translation happens. We are targeting NestJS because its architecture—Decorators, Modules, and Dependency Injection—maps 1:1 with Spring Boot.
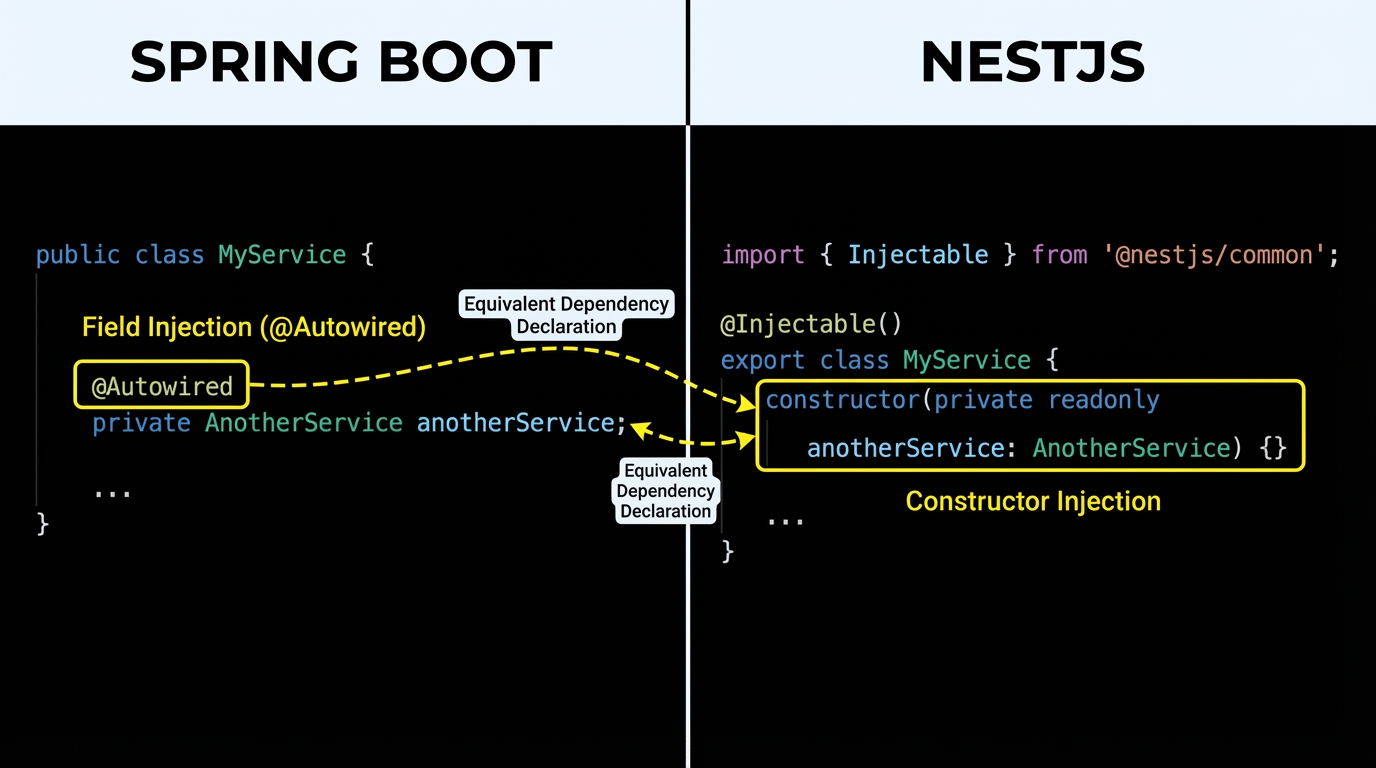
1. Dependency Injection
The Agent must convert field injection (@Autowired) to constructor injection, which is the standard in TypeScript/NestJS.
Java Source:
@Service
public class UserService {
@Autowired
private UserRepository userRepository;
public User getUser(Long id) {
return userRepository.findById(id).orElseThrow();
}
}
Agent Generated NestJS:
@Injectable()
export class UserService {
// Agent identifies @Autowired and converts to Constructor Injection
constructor(
@InjectRepository(User)
private readonly userRepository: Repository<User>,
) {}
async getUser(id: number): Promise<User> {
// Agent converts blocking call to async/await
const user = await this.userRepository.findOneBy({ id });
if (!user) throw new NotFoundException();
return user;
}
}
2. Managing Dependencies (Maven to NPM)
One of the hardest parts of migration is the ecosystem shift. pom.xml dependencies do not map one-to-one with package.json.
The Agent utilizes a lookup dictionary (which it can expand via web search tools) to resolve these:
| Java Paradigm | Maven Artifact | Node.js Equivalent | Package |
|---|---|---|---|
| Validation | hibernate-validator |
class-validator |
class-validator, class-transformer |
| Utility | commons-lang3 |
Lodash | lodash |
| HTTP Client | RestTemplate |
Axios | @nestjs/axios |
| Logging | slf4j |
Winston/Pino | winston |
The Agent must parse the pom.xml, extract versions, find the compatible Node version, and generate the package.json before writing application code.
Phase 3: The Self-Healing Feedback Loop
This is the differentiator between a “Code Generator” and an “Agent.”
Code generated by LLMs will contain bugs. It might use a Java method signature that doesn’t exist in JavaScript (e.g., string.equals()), or mishandle Promise resolution.
To solve this, we implement a Self-Healing Loop.
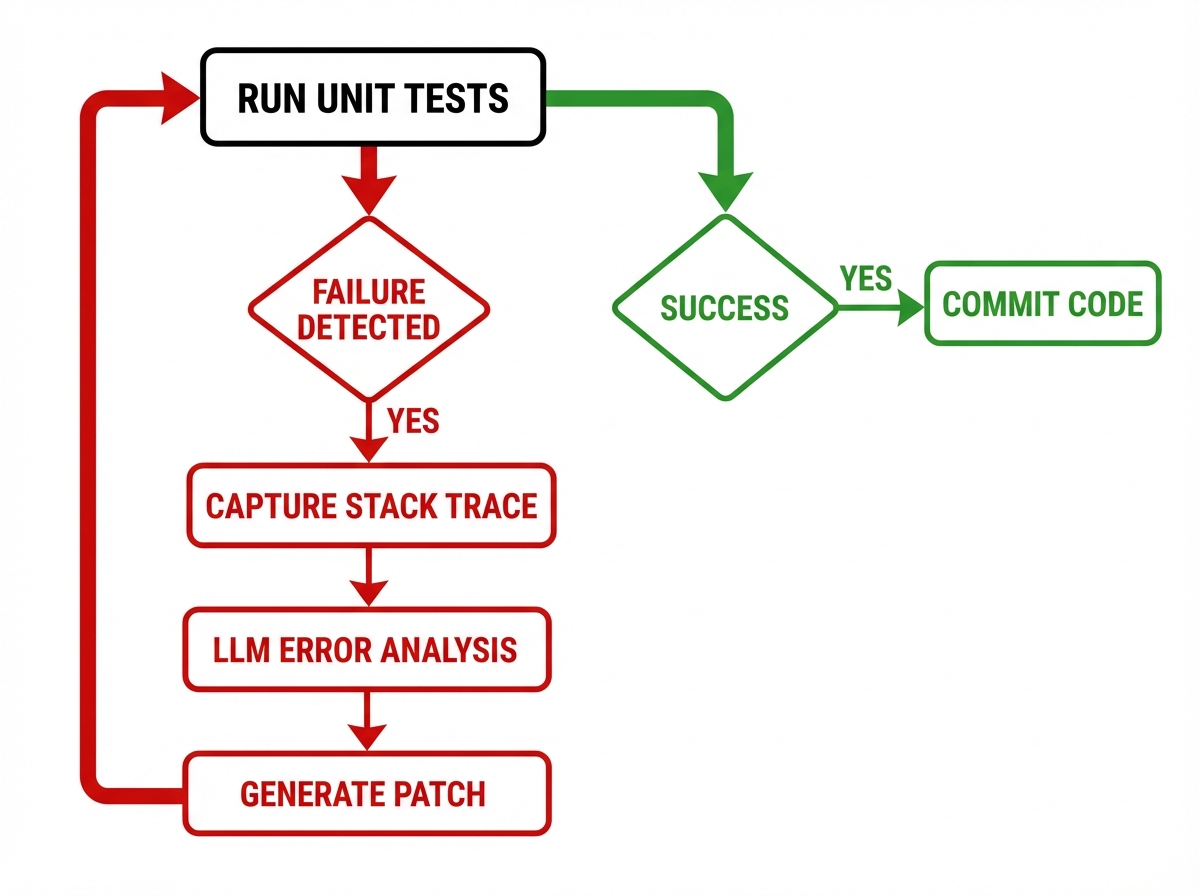
Step 1: Test Generation
Immediately after transpiling UserService.ts, the Agent is tasked to write UserService.spec.ts. It uses the logic from the original Java UserServiceTest.java to ensure functional parity.
Step 2: Execution & Capture
The Agent executes the test suite using a sandbox runner.
npm test src/users/user.service.spec.ts
Step 3: Analysis & Patching
If the test fails, the Agent does not stop. It captures the stderr and the stack trace. It feeds this error back into the LLM context along with the source code.
The Prompt Chain:
- Context: “You wrote this Node.js service based on this Java logic.”
- Observation: “Running the test resulted in
TypeError: Cannot read properties of undefined (reading 'findOne').” - Instruction: “Analyze the stack trace. Reasoning step-by-step, identify why the mock was not injected correctly. Patch the code.”
Example Scenario: The “Async” Trap A common failure mode is treating asynchronous Node code as synchronous Java code.
- Agent Draft 1:
users.forEach(user => { // ERROR: saving inside forEach without Promise.all this.repo.save(user); }); - Test Result: Test finishes before data is saved. Assertion fails.
- Agent Analysis: “I detected a race condition.
forEachdoes not await promises. I need to switch tofor...oforPromise.all.” - Agent Patch:
await Promise.all(users.map(user => this.repo.save(user)));
This loop continues up to a maximum retry count (e.g., 5 attempts) until the tests pass.
Database and Entity Migration
Migration isn’t just code; it’s data. Moving from Hibernate/JPA to TypeORM or Prisma requires careful handling of relationships.
The Lazy Loading Problem
Java Hibernate heavily relies on Lazy Loading. You fetch a User, and when you call user.getOrders(), Hibernate silently queries the DB.
Node.js ORMs generally default to explicit loading to avoid the “N+1 Query Problem.”
The Agent must detect @OneToMany(fetch = FetchType.LAZY) in the Java Entity and transform the consuming service code to explicitly request relations.
Java (Implicit):
// Logic inside a Service
User user = repo.findById(1);
return user.getOrders().size(); // Hibernate triggers query here
Node.js (Explicit - Generated by Agent):
If the Agent simply translates the logic, it will crash because user.orders is undefined. The Agent must recognize the context and rewrite the query:
// Agent rewrite
const user = await this.repo.findOne({
where: { id: 1 },
relations: ['orders'] // Explicit join added by Agent
});
return user.orders.length;
Implementation Guide: The Controller Agent
Let’s look at the specific implementation of the “Controller Migration” step using Python and LangChain.
from langchain.chat_models import ChatOpenAI
from langchain.schema import SystemMessage, HumanMessage
def migrate_controller(java_code, service_interface_ts):
chat = ChatOpenAI(model="gpt-4-turbo", temperature=0)
system_prompt = """
You are a Senior Backend Engineer migrating Spring Boot to NestJS.
Rules:
1. Map @RequestMapping to @Controller.
2. Map @GetMapping, @PostMapping to NestJS decorators.
3. Ensure all service calls use 'await'.
4. Use DTOs defined in the provided context.
5. Return strict TypeScript types.
"""
user_prompt = f"""
### Java Source:
{java_code}
### Associated TypeScript Service Interface:
{service_interface_ts}
Convert this Controller to NestJS. Output ONLY the code.
"""
response = chat([
SystemMessage(content=system_prompt),
HumanMessage(content=user_prompt)
])
return response.content
def verification_loop(file_path, test_path):
attempts = 0
while attempts < 5:
result = run_npm_test(test_path)
if result.success:
return True
# Self-Healing Step
error_log = result.stderr
current_code = read_file(file_path)
patch = agent_fix_code(current_code, error_log)
write_file(file_path, patch)
attempts += 1
raise Exception("Failed to converge on working code.")
This Python script represents the orchestrator. It holds the state, manages file I/O, and executes the shell commands that provide the “reality check” for the LLM.
Advanced Edge Cases
In production migrations, several edge cases typically break simple conversion tools.
1. Static Contexts & Singletons
Java developers often use public static methods for utilities or holding state. In a Node.js microservice context, global mutable state is dangerous due to the single-threaded event loop serving all requests. The Agent must detect static fields that are mutated and refactor them into request-scoped providers or Redis-backed state.
2. ThreadLocal
Spring Security often stores user context in ThreadLocal.
- Java:
SecurityContextHolder.getContext().getAuthentication() - Node: The Agent must identify this pattern and introduce
AsyncLocalStorage(ALS) or pass therequestobject through the method chain (Context Propagation).
3. Synchronized Blocks
Java uses synchronized for thread safety. Node.js is single-threaded, so standard concurrency issues don’t apply the same way, but race conditions on external resources (DB, File IO) do. The Agent must translate synchronized blocks into distributed locks (e.g., using Redlock) if the intent was to protect a shared resource across instances, or remove them entirely if they were protecting in-memory state.
Conclusion
Migrating from Java to Node.js is no longer a brute-force manual effort. By implementing an Agentic Workflow, we move from “Syntax Translation” to “Logic Porting.”
The combination of AST Analysis for deep understanding, Paradigm Mapping for idiomatic translation, and a Self-Healing Feedback Loop for functional verification allows us to automate 70-80% of the migration effort.
The remaining 20%? That’s where you, the Senior Engineer, come in. You review the architecture, optimize the database queries that the Agent mapped too literally, and handle the complex business logic that requires human intuition. But the boilerplate, the DTOs, the basic CRUD, and the test suites? Let the Agents handle that.