How I built an AI blogger Agent using N8N,Github and Jekyll

In the current landscape of software engineering, “content creation” is often viewed as a secondary concern—a distraction from shipping code. However, technical documentation and knowledge sharing are critical components of system design. The problem isn’t the lack of knowledge; it’s the friction involved in the pipeline: ideation, drafting, asset creation, formatting, and deployment.
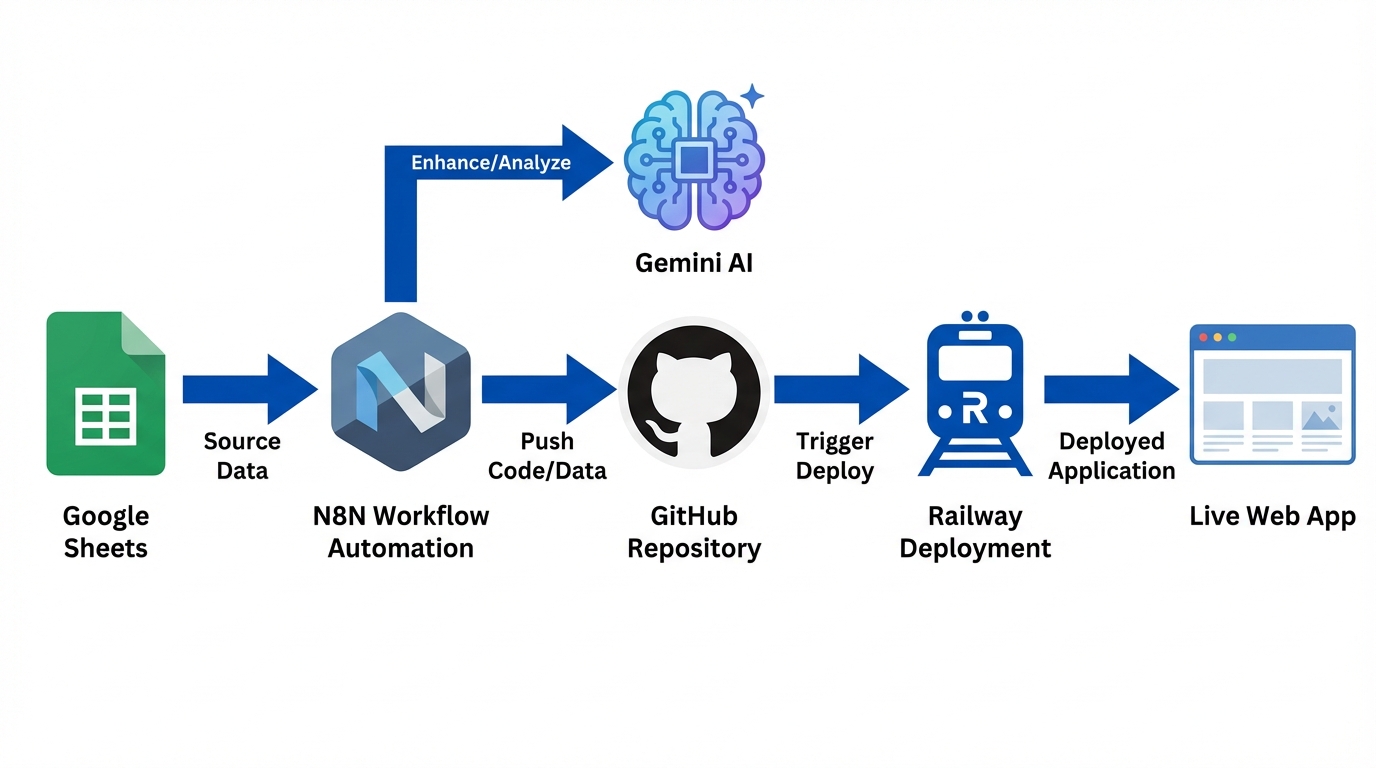
I decided to solve this not by writing more, but by engineering a solution. I built an autonomous AI Agent that functions as a full-stack technical blogger. This isn’t a simple wrapper around ChatGPT that spits out generic text. This is a deterministic, multi-step pipeline that orchestrates planning, visual asset generation, code-aware writing, version control integration, and continuous deployment.
This post creates a deep dive into the architecture of this system, specifically focusing on the orchestration layer (n8n), the storage/versioning layer (GitHub), and the presentation layer (Jekyll on Railway).
The Core Philosophy: Agents vs. Generators
Before looking at the code, we must distinguish between Generative AI and Agentic AI.
- Generative AI is input-output. You give a prompt; you get text.
- Agentic AI involves reasoning, planning, and tool usage.
My goal was to build the latter. An agent that looks at a topic, thinks about what diagrams are needed to explain that topic, generates those diagrams using external tools, hosts them, and then writes the article referencing those specific assets.
Part 1: The Backend Orchestration (n8n)
The brain of this operation is n8n. While I could have written this in Python using LangChain or Swarm, n8n provides a visual interface for flow control which is invaluable when debugging complex asynchronous chains involving file buffers and API calls.
1. The Trigger and State Management
The workflow is state-driven. We don’t want to regenerate old blogs, nor do we want to hallucinate topics. I use Google Sheets as a lightweight database.
The Data Structure:
Topic: The technical subject (e.g., “Implementing Rate Limiting with Redis”).-
Status:PendingProcessingDone. Date: Timestamp.
The n8n workflow begins with a Google Sheets Trigger that fetches rows where Status == Pending.
// Sample JSON Output from the Trigger Node
[
{
"Topic": "Deep Dive into Kubernetes Networking",
"Status": "Pending",
"RowNumber": 4
}
]
2. The Planner Agent (Gemini Pro)
This is the most critical architectural decision. I do not ask the LLM to write the blog yet. If you ask an LLM to “write a blog with images,” it will hallucinate URLs (e.g., ).
Instead, I use a “Planner” node. I feed the topic to Gemini Pro with a system prompt designed to act as a Technical Art Director.
System Prompt Strategy:
“You are a Technical Art Director. Analyze the following topic. Outline a plan for 3-5 visual assets required to explain this concept. For each asset, provide a detailed image generation prompt and a specific filename.”
The output is forced into a structured JSON format (using n8n’s JSON parser):
{
"assets": [
{
"type": "architecture_diagram",
"filename": "k8s-networking-flow.png",
"prompt": "High contrast technical diagram, kubernetes pod communication, flat vector style..."
},
{
"type": "hero_image",
"filename": "k8s-hero.png",
"prompt": "Cyberpunk style container ship, digital ocean, isometric 3d render..."
}
]
}
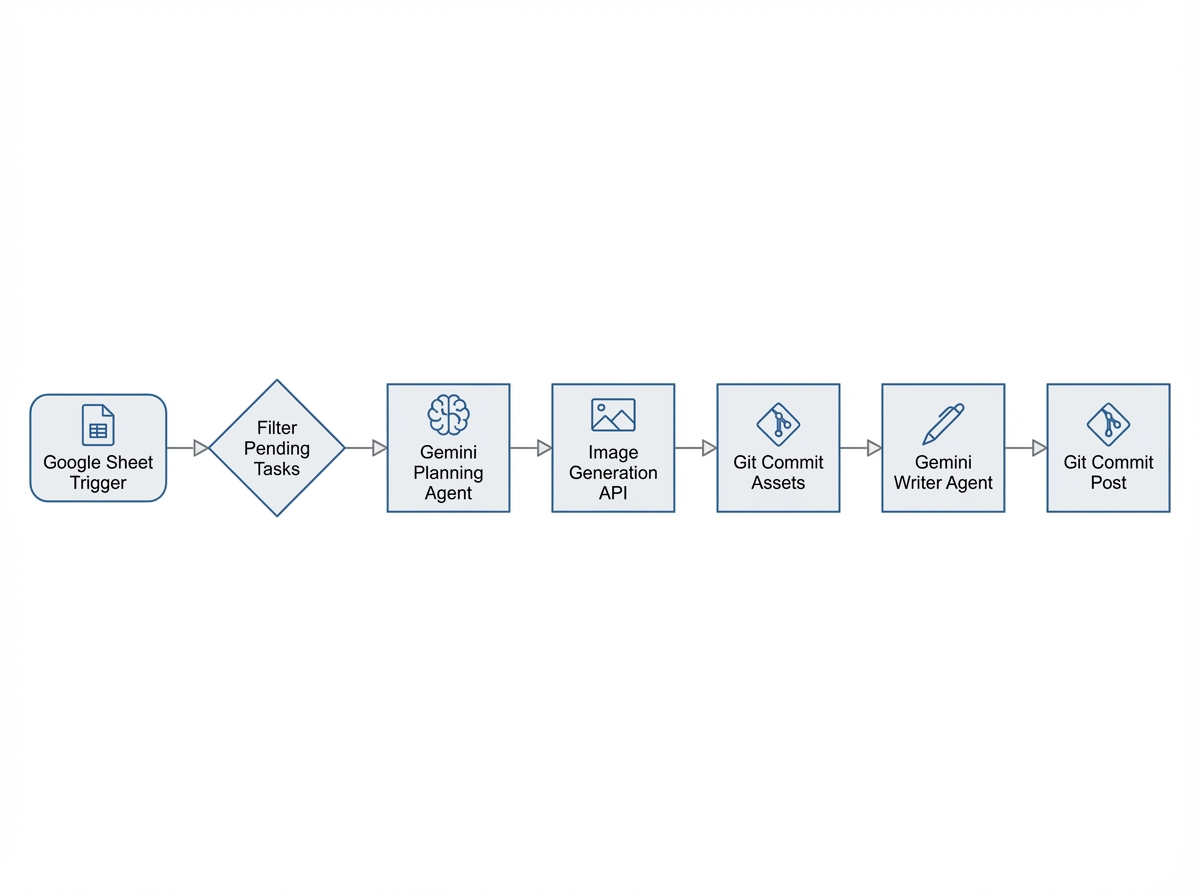
3. Asset Generation and Binary Handling
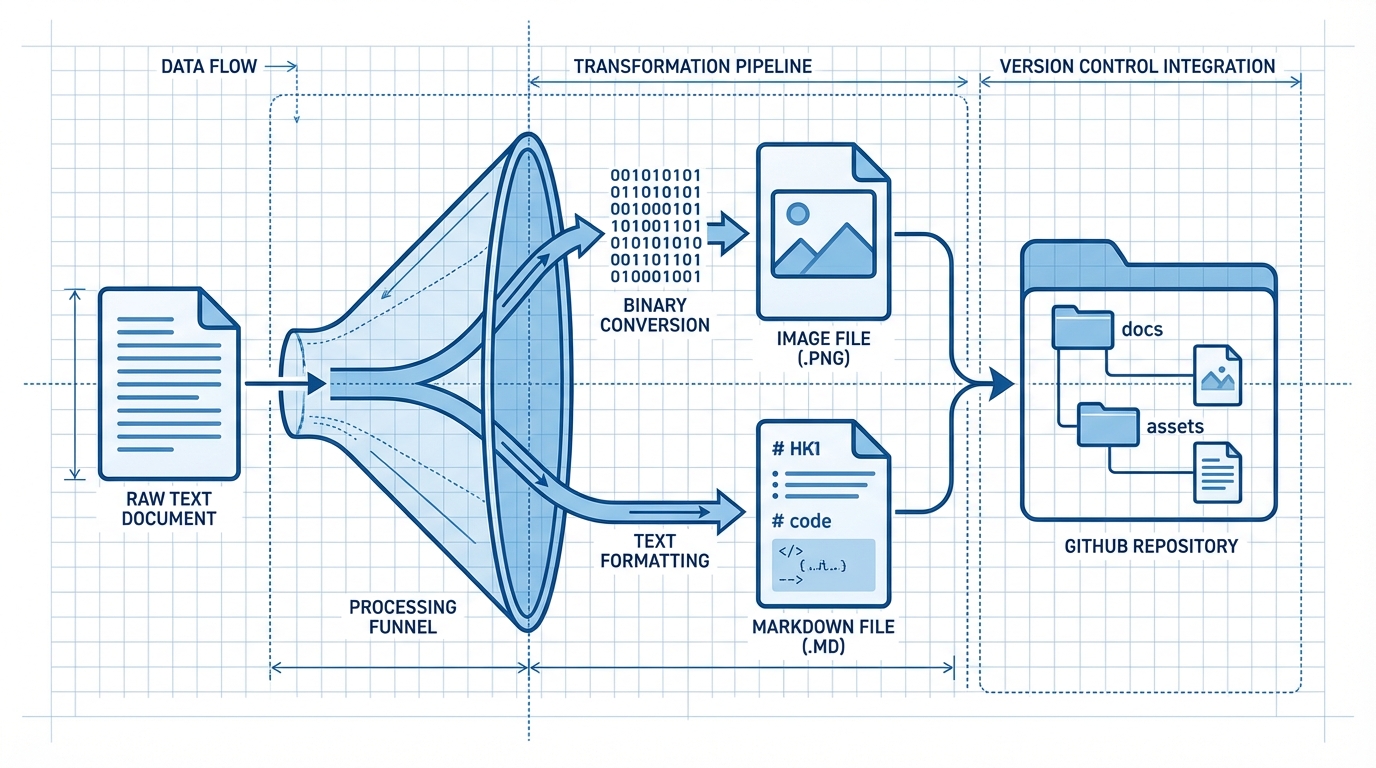
Once the plan is generated, n8n iterates over the assets array. This is where we hit a common hurdle in low-code automation: Binary Data Handling.
The workflow makes a call to an Image Generation API (e.g., OpenAI DALL-E 3 or Stability AI). The API returns a URL or a Base64 string. We cannot simply pass a URL to the writer; we need to own the asset to prevent link rot.
The Process:
- HTTP Request: Send prompt to Image Gen API.
- Buffer Handling: Download the image to n8n’s memory.
- Base64 Conversion: GitHub’s API requires file content to be Base64 encoded.
// n8n Function Node: Prepare for GitHub API
const binaryData = items[0].binary.data;
const base64String = binaryData.toString('base64');
return {
json: {
path: `assets/images/${generatedFilename}`,
message: `chore: auto-add asset ${generatedFilename}`,
content: base64String,
branch: "main"
}
};

4. Committing Assets to GitHub
I interact directly with the GitHub REST API. This is cleaner than trying to use git commands inside a Docker container within n8n.
Endpoint: PUT /repos/{owner}/{repo}/contents/{path}
We loop through every generated image and commit it to the assets/images/ directory in the repository. Crucially, after the commit is successful, we construct the public raw URL or the CDN URL for that image.
The Context Map: We aggregate the results into a context map that looks like this:
{
"hero": "https://blogs.buildwithmanish.com/assets/images/k8s-hero.png",
"diagram_1": "https://blogs.buildwithmanish.com/assets/images/k8s-networking-flow.png"
}
5. The Writer Agent (Context Injection)
Now, and only now, do we invoke the Writer Agent. We pass the original topic and the Context Map of valid image URLs.
The Prompt:
“Write a deep-dive technical blog post about . You MUST use the following image URLs in your markdown. Place the hero image after the front matter. Place the architecture diagram in the ‘Network Concepts’ section. Use strict Markdown syntax. Include Jekyll Front Matter.”
This ensures the LLM writes the content around the images we actually possess, rather than making up images that don’t exist.
6. Final Commit and Cleanup
The final step in n8n is taking the Markdown output from the Writer Agent and committing it to the _posts/ directory on GitHub. The filename is auto-generated based on the date and title (slugified), e.g., 2025-12-18-k8s-networking.md.
Finally, the Google Sheet row is updated from Pending to Done.
Part 2: The Frontend (Jekyll & Railway)
The backend handles the “Supply” side. The frontend handles the “Demand” side. I chose Jekyll because it transforms Markdown into static HTML. It is secure, fast, and requires zero database maintenance on the read path.
1. The Build Pipeline
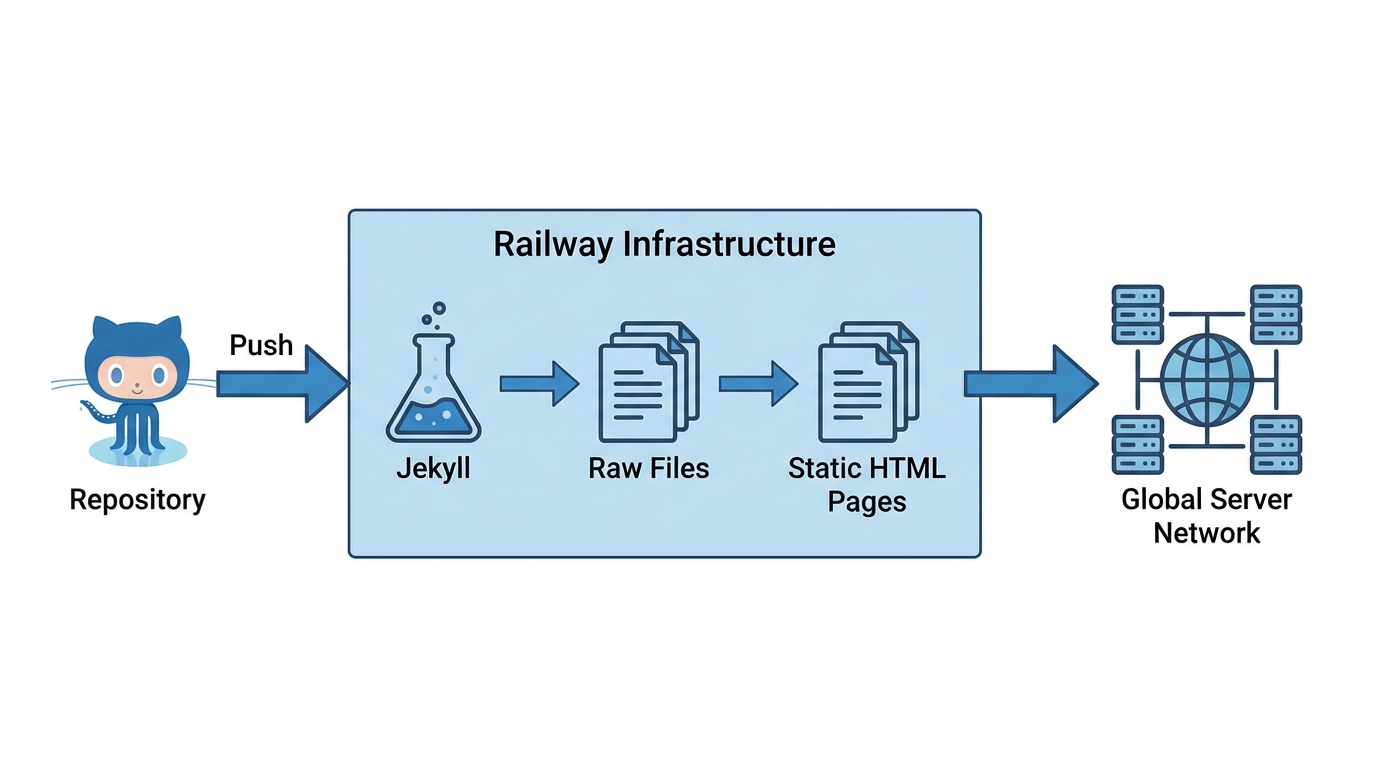
The deployment architecture is completely event-driven.
- Event: n8n commits a new
.mdfile to themainbranch on GitHub. - Trigger: Railway (my hosting provider) detects the commit via Webhook.
- Build: Railway pulls the repo and runs the Jekyll build command.
Railway Configuration (railway.json or Build Command):
bundle install && bundle exec jekyll build
This generates the _site folder, which Railway serves via NGINX. The entire process from “Commit” to “Live URL” takes approximately 45 seconds.
2. Frontend Engineering: Beyond Default Themes
While Jekyll themes exist, I built a custom frontend to support the specific requirements of a technical blog.
A. Multi-Tag Filtering
Technical posts often cross domains (e.g., “DevOps” and “AWS”). I implemented a filtering system using Vanilla JavaScript.
In the Jekyll template (home.html), I generate data attributes:
<div class="post-card" data-tags="n8n, automation, ai">
<!-- Post Content -->
</div>
The JavaScript simply toggles visibility:
function filterPosts(selectedTag) {
const posts = document.querySelectorAll('.post-card');
posts.forEach(post => {
const tags = post.getAttribute('data-tags').split(', ');
if (tags.includes(selectedTag) || selectedTag === 'all') {
post.style.display = 'block';
} else {
post.style.display = 'none';
}
});
}
B. Image Lightbox
Since the AI generates detailed architecture diagrams, users need to zoom in. I implemented a lightbox feature that intercepts clicks on any image within the .post-content div.
document.querySelectorAll('.post-content img').forEach(image => {
image.addEventListener('click', e => {
const src = e.target.src;
// Logic to open modal overlay with this src
openLightbox(src);
});
});
C. Search Functionality
For a static site, server-side search isn’t an option. I avoided heavy libraries like Algolia for this use case. Instead, I use a build-time generated JSON index.
In search.json (a Liquid template):
---
layout: null
---
[
{
"title": "Top 5 Programming Languages to learn in 2026",
"url": "/deep-dive/career-growth/software-engineering/system-design/tech-trends/2025/12/31/top-5-programming-languages-to-learn-in-2026.html",
"tags": "",
"content": " # Introduction: The Confession of a Senior Engineer I have a confession to make. For years, I was wrong. I was wrong because I fell into the trap that many content creators and tech leads fall into: the trap of the linear roadmap. I used..."
} ,
{
"title": "Relational Database Management System: An Engineering Deep-Dive",
"url": "/deep-dive/database-systems/sql/data-modeling/backend-engineering/2025/12/30/relational-database-management-system.html",
"tags": "",
"content": " Despite the meteoric rise of NoSQL, time-series, and vector databases in the last decade, the Relational Database Management System (RDBMS) remains the immutable backbone of global enterprise software. Whether it’s financial ledgers, inventory management, or user identity systems, the relational model's promise of ACID (Atomicity,..."
} ,
{
"title": "Textbook for Excel Exam",
"url": "/deep-dive/excel-mastery/data-analysis/spreadsheet-engineering/certification/2025/12/29/textbook-for-excel-exam.html",
"tags": "",
"content": " # Introduction In the world of data engineering and business intelligence, Microsoft Excel remains the ubiquitous "first draft" of data analysis. While Python, SQL, and Tableau dominate big data pipelines, Excel is where the business world lives. It is effectively a functional programming environment coupled with a two-dimensional..."
} ,
{
"title": "Reactive Architecture in Flutter: Mastering BLoC for Scalable State Management",
"url": "/deep-dive/flutter/state-management/bloc/reactive-architecture/2025/12/18/reactive-architecture-in-flutter-mastering-bloc-for-scalable-state-management.html",
"tags": "",
"content": " When building scalable mobile applications, the ease of Flutter’s `setState` is a siren song. It works beautifully for a counter app or a simple toggle, but as your application grows into an enterprise-grade solution, coupling business logic tightly with UI widgets creates a codebase that..."
} ,
{
"title": "Implementing Agentic Workflows for Java-to-Node.js Migration",
"url": "/deep-dive/generative-ai/legacy-migration/java-spring/nodejs-nestjs/2025/12/18/implementing-agentic-workflows-for-javatonodejs-migration.html",
"tags": "",
"content": " Legacy migration is the "dark matter" of software engineering: we know it makes up a massive portion of the enterprise universe, yet we struggle to observe it directly without getting sucked into a black hole of regression testing and lost business logic. For the last decade, the migration..."
} ,
{
"title": "How I built an AI blogger Agent using N8N,Github and Jekyll",
"url": "/deep-dive/n8n/ai-automation/jekyll/system-design/2025/12/18/how-i-built-an-ai-blogger-agent-using-n8ngithub-and-jekyll.html",
"tags": "",
"content": " In the current landscape of software engineering, "content creation" is often viewed as a secondary concern—a distraction from shipping code. However, technical documentation and knowledge sharing are critical components of system design. The problem isn't the lack of knowledge; it's the friction involved in the pipeline: ideation, drafting,..."
} ,
{
"title": "How I built an AI blogger Agent using N8N and Jekyll",
"url": "/deep-dive/n8n/generative-ai/jekyll/automation/2025/12/18/how-i-built-an-ai-blogger-agent-using-n8n-and-jekyll.html",
"tags": "",
"content": "As engineers, we often suffer from the “cobbler’s children” syndrome. We build complex, scalable systems for clients and employers, yet our own personal portfolios and blogs gather dust. The friction of context-switching from coding to writing, finding assets, and managing deployments often kills the momentum before a post is even..."
} ,
{
"title": "Mastering Razorpay Webhooks: Architecting an Idempotent, Event-Driven Ingestion Engine",
"url": "/deep-dive/system-design/payments/event-driven-architecture/razorpay/2025/12/17/mastering-razorpay-webhooks-architecting-an-idempotent-eventdriven-ingestion-engine.html",
"tags": "",
"content": "Introduction: The Deceptive Simplicity of Webhooks Integrating a payment gateway like Razorpay often starts with a false sense of security. The documentation shows a happy path: user pays, Razorpay calls your webhook, you update the database, and ship the product. In a development environment with one request per minute, this..."
} ,
{
"title": "Java Concurrency at Scale: Migrating from Thread Pools to Virtual Threads",
"url": "/deep-dive/java/concurrency/virtual-threads/software-architecture/2025/12/17/java-concurrency-at-scale-migrating-from-thread-pools-to-virtual-threads.html",
"tags": "",
"content": "For the better part of two decades, Java concurrency has been a negotiation with the Operating System. We built high-throughput systems on the back of the “One-Thread-Per-Request” model, eventually hitting the hard ceiling of OS resource limits. We patched this with thread pools, and when that wasn’t enough, we twisted..."
} ,
{
"title": "Escaping the if (isAdmin) Trap: Implementing Scalable RBAC and ABAC in Node.js",
"url": "/deep-dive/nodejs/security/rbac/abac/system-design/2025/12/17/escaping-the-if-isadmin-trap-implementing-scalable-rbac-and-abac-in-nodejs.html",
"tags": "",
"content": "We have all written it. The line of code that marks the beginning of the end for a scalable codebase: if (user.isAdmin || (user.role === 'manager' &amp;&amp; resource.ownerId === user.id)) { // Allow logic } It starts innocently enough. A boolean flag here, a string check there. But as your..."
} ,
{
"title": "Building a Virtual Data Analyst: Architecting Agentic AI Workflows over Power BI",
"url": "/deep-dive/gen-ai/power-bi/agentic-workflows/python/2025/12/17/building-a-virtual-data-analyst-architecting-agentic-ai-workflows-over-power-bi.html",
"tags": "",
"content": "In the rush to adopt Generative AI, organizations have flooded their backlogs with “Chat with your Data” initiatives. Most of these projects follow a predictable, often disappointing, pattern: a text-to-SQL layer slapped on top of a raw data warehouse. While this works for simple questions (“How many widgets did we..."
} ,
{
"title": "Beyond the Happy Path: Architecting Fault-Tolerant Recurring Payments with Razorpay",
"url": "/technical/deep-dive/2025/12/17/beyond-the-happy-path-architecting-faulttolerant-recurring-payments-with-razorpay.html",
"tags": "",
"content": "The Illusion of the “Happy Path” In the world of distributed systems, the “happy path” is a sedative. It lulls engineers into a false sense of security where networks never partition, latency is zero, and customers always have sufficient funds in their bank accounts. When building one-off payment flows, you..."
} ,
{
"title": "Beyond GET and SET: Architecting Resilient Distributed Caching Patterns for Microservices",
"url": "/deep-dive/system-design/redis/distributed-systems/microservices/2025/12/17/beyond-get-and-set-architecting-resilient-distributed-caching-patterns-for-microservices.html",
"tags": "",
"content": "Introduction In the infancy of a backend application, caching is often treated as a simple key-value store optimization—a sprinkle of “magic dust” to speed up slow SQL queries. Developers implement a basic client.get() and client.set(), push to production, and watch latencies drop. It feels victorious. However, as traffic scales and..."
}
]
The frontend fetches this JSON on page load (or on first focus of the search bar) and performs a client-side filter. It’s incredibly fast for blogs with under 1,000 posts.
Advanced Considerations and Edge Cases
Building a “Happy Path” agent is easy. Building one that runs autonomously requires handling failure.
1. Hallucination Control
Occasionally, the Image Gen API fails or returns a policy violation error.
- Mitigation: The n8n workflow has error paths. If an image fails to generate, the workflow substitutes a generic “placeholder technical pattern” image from a pre-defined bucket. This ensures the blog post doesn’t break due to a missing asset.
2. Markdown Sanitization
LLMs sometimes include conversational filler (“Here is your blog post…”) before the Front Matter.
- Mitigation: I use a Regex extraction node in n8n to strip everything before the first
---and after the last character of the content.
3. GitHub API Rate Limits
Committing 7 images + 1 markdown file in rapid succession can trigger secondary rate limits on GitHub if not careful.
- Mitigation: I implemented a
Waitnode in n8n, introducing a 2-second delay between commit calls. This also prevents race conditions if multiple workflows trigger simultaneously (though n8n execution mode is set to strictly sequential for this workflow).
Conclusion: The ROI of Automation
This system demonstrates the power of Composite AI—combining deterministic code (n8n/GitHub/Jekyll) with probabilistic AI (LLMs).
By decoupling the Planner from the Writer and managing assets programmatically, we achieve a level of consistency and quality that simple “Prompt-to-Blog” tools cannot match.
Here is a comparison of this architecture versus standard AI generation:

The pipeline is now live. Every time I have an idea, I add a row to Google Sheets. My agent handles the rest, allowing me to focus on high-level architecture rather than CSS tweaks and file management.
Next Steps
The next iteration of this agent will include:
- SEO Optimization: An additional LLM step to analyze keywords and inject them into the metadata.
- Social Media Broadcasting: Automatically generating LinkedIn and Twitter threads based on the final Markdown and scheduling them via n8n.
- Interactive Components: Experimenting with generating Mermaid.js code instead of static images for diagrams, allowing for render-time interactivity.